


A Revolução da Inteligencia Artificial
Re: A Revolução da Inteligencia Artificial
BearManBull Escreveu:
Disse que é um dos grandes problemas. Nao disse que era o unico.
Larga e sem degradação não é a mesma coisa. Há que entender/identificar a causa da degradação (aumentar a janela pode apenas mitigar o problema e não resolvê-lo a um nível fundamental). Isto aponta já para dois potenciais problemas e não um. Também não estou a entender muito bem a questão do reset na sequência do mesmo bullet point pois isto já passa para lá da janela de contexto em si e começa a entrar na questão do conhecimento persistente. Ou seja, um terceiro problema. Eu não estou a discordar dos problemas assinalados, estou a apontar que são vários problemas que estão a ser aglomerados no mesmo bullet point mas que, na verdade, são problemas de natureza diferente.
O que, para mim, aponta para causas mais profundas de arquitectura (não apenas de recursos), em linha com o que venho expondo.
BearManBull Escreveu:Falta ali ou uma context window de terabytes ou um sistema orquestrador que guarda e recupera a informaçao por exemplo por MCP.
Convém também notar que aumentar a janela de contexto tem custos computacionais (de hardware, de energia, de velocidade a gerar a completion e, possivelmente até, de qualidade da propria completion). Aumentar a janela de contexto deverá ser feito judiciosamente. Caso contrário arrisca-se overkill e possivelmente criando novos handicaps. Assumindo uma capacidade intrínseca de inferência constante, se de cada vez que o modelo vai gerar a completion, tem uma janela de contexto colossal para digerir, provavelmente o resultado vai-se degradar. Se assim for, a solução é continuar a escalar os modelos. Precisamente o que tinhas alegado antes que não está a dar sinais de que dê frutos:
BearManBull Escreveu:MarcoAntonio Escreveu:Por enquanto, bigger/better tem sido o foco da Google, OpenAI e companhia (o GPT5 talvez tenha já dado um quê de mudança de direcção) mas, mesmo que os principais players se foquem na capacidade bruta dos modelos, há o potencial para o resto do ecossistema para tentar retirar o melhor partido dos modelos existentes (como por exemplo, aplicações especializadas).
Esse foco tem vindo a ser demonstado que nao está a dar frutos.
FLOP - Fundamental Laws Of Profit
1. Mais vale perder um ganho que ganhar uma perda, a menos que se cumpra a Segunda Lei.
2. A expectativa de ganho deve superar a expectativa de perda, onde a expectativa mede a
__.amplitude média do ganho/perda contra a respectiva probabilidade.
3. A Primeira Lei não é mesmo necessária mas com Três Leis isto fica definitivamente mais giro.
-

- Administrador Fórum
- Mensagens: 41980
- Registado: 4/11/2002 22:16
- Localização: Porto
Re: A Revolução da Inteligencia Artificial
“It is not the strongest of the species that survives, nor the most intelligent, but rather the one most adaptable to change.”
― Leon C. Megginson
― Leon C. Megginson
-

- Mensagens: 11973
- Registado: 15/2/2011 11:59
- Localização: 22
Re: A Revolução da Inteligencia Artificial
BearManBull Escreveu:O meu ponto nao foi falar em AGIs e continuam a bater na mesma tecla. O ponto é eliminar postos de trabalho de pessoal na base das empresas que acaba por ser onde se concentra o grosso da força de trabalho.
Bear, tu levantaste/colocaste a questão logo num dos primeiros posts desta troca:
BearManBull Escreveu:
Nao é preciso ter AGI para criar uma estratégia de defesa num caso judical grande, mas é preciso ser capaz de ler muita informaçao e pescar o que é relevante.
Com prompts atomicos os LLMs fazem um bom serviço, outra coisa é passar um arquivo com imagens, diagramas, relatos, relatorios, etc tudo com conteudos difusos que é acontece ao ser humano.
Principalmente quando se tenta coisas do estilo, "ok agora corrige este ponto", "agora corrige outro ponto" - morre na praia.
A minha questão é precisamente como é que tu sabes isso (o que alegas em cima, que não é preciso). Ou, por outras palavras, como é que tu determinas que não possuir uma inteligência na verdadeira acepção da palavra não está (pelo menos parcialmente) por detrás dos problemas de que estás a falar.
BearManBull Escreveu:Na generalidade os LLMs conseguem fazer em termos micro o mesmo trabalho que fazem essas pessoas falta é a capacidade de acompanhamento e enquadramento para colaborar num processo empresarial e isso é por contexto diario que vao guardando e eliminando o que nao é necessário. Falta ali ou uma context window de terabytes ou um sistema orquestrador que guarda e recupera a informaçao por exemplo por MCP.
Aqui, na primeira alternativa, voltas a insistir meramente numa questão de recursos. Alargar o recurso (janela de contexto maior) não altera a natureza do processo. Com a segunda parte já consigo concordar. O sistema orquestrador se calhar então é o mecanismo que se substitui (ou complementa) a falta de uma verdadeira inteligência...
FLOP - Fundamental Laws Of Profit
1. Mais vale perder um ganho que ganhar uma perda, a menos que se cumpra a Segunda Lei.
2. A expectativa de ganho deve superar a expectativa de perda, onde a expectativa mede a
__.amplitude média do ganho/perda contra a respectiva probabilidade.
3. A Primeira Lei não é mesmo necessária mas com Três Leis isto fica definitivamente mais giro.
-
- Administrador Fórum
- Mensagens: 41980
- Registado: 4/11/2002 22:16
- Localização: Porto
Re: A Revolução da Inteligencia Artificial
Outro exemplo de hemulaçao é a maquina de hemodialise.
Emula o rim.
Emula o rim.
“It is not the strongest of the species that survives, nor the most intelligent, but rather the one most adaptable to change.”
― Leon C. Megginson
― Leon C. Megginson
-
- Mensagens: 11973
- Registado: 15/2/2011 11:59
- Localização: 22
Re: A Revolução da Inteligencia Artificial
Há que spearar dois conceitos.
O idilico/cientifico de atingir uma máquina pensante.
O prático de atingir modelos que substituem seres humanos nos postos de trabalho.
Os LLM longe de serem maquinas pensantes sao o melhor que se conseguiu até ao momento em termos de emular pensamento humano e fazem-no de forma ás vezes assustadoras. Diria que boa parte da populaçao se for exposta a um teste de decidir se esta a falar com uma maquina ou com um humano nao consegue fazer a distinçao.
No geral os LLMs sao estrondosos como assistentes em micro tarefas, fazem muitas tarefas que estavam restritas até há pouco tempo a seres pensantes.
O meu ponto nao foi falar em AGIs e continuam a bater na mesma tecla. O ponto é eliminar postos de trabalho de pessoal na base das empresas que acaba por ser onde se concentra o grosso da força de trabalho.
Na generalidade os LLMs conseguem fazer em termos micro o mesmo trabalho que fazem essas pessoas falta é a capacidade de acompanhamento e enquadramento para colaborar num processo empresarial e isso é por contexto diario que vao guardando e eliminando o que nao é necessário. Falta ali ou uma context window de terabytes ou um sistema orquestrador que guarda e recupera a informaçao por exemplo por MCP.
No caso de Portugal estaria a apontar para salarios na ordem dos 1200 euros. Portanto ter o modelo a correr nao poderia exceder esse valor senao obviamente que a empresa mantem o colaborador.
O idilico/cientifico de atingir uma máquina pensante.
O prático de atingir modelos que substituem seres humanos nos postos de trabalho.
Os LLM longe de serem maquinas pensantes sao o melhor que se conseguiu até ao momento em termos de emular pensamento humano e fazem-no de forma ás vezes assustadoras. Diria que boa parte da populaçao se for exposta a um teste de decidir se esta a falar com uma maquina ou com um humano nao consegue fazer a distinçao.
No geral os LLMs sao estrondosos como assistentes em micro tarefas, fazem muitas tarefas que estavam restritas até há pouco tempo a seres pensantes.
O meu ponto nao foi falar em AGIs e continuam a bater na mesma tecla. O ponto é eliminar postos de trabalho de pessoal na base das empresas que acaba por ser onde se concentra o grosso da força de trabalho.
Na generalidade os LLMs conseguem fazer em termos micro o mesmo trabalho que fazem essas pessoas falta é a capacidade de acompanhamento e enquadramento para colaborar num processo empresarial e isso é por contexto diario que vao guardando e eliminando o que nao é necessário. Falta ali ou uma context window de terabytes ou um sistema orquestrador que guarda e recupera a informaçao por exemplo por MCP.
No caso de Portugal estaria a apontar para salarios na ordem dos 1200 euros. Portanto ter o modelo a correr nao poderia exceder esse valor senao obviamente que a empresa mantem o colaborador.
Editado pela última vez por BearManBull em 30/8/2025 1:00, num total de 1 vez.
“It is not the strongest of the species that survives, nor the most intelligent, but rather the one most adaptable to change.”
― Leon C. Megginson
― Leon C. Megginson
-
- Mensagens: 11973
- Registado: 15/2/2011 11:59
- Localização: 22
Re: A Revolução da Inteligencia Artificial
Rolling_Trader Escreveu:O paper que citou não diz que as janelas de contexto não são "suficientemente longos", disserta sim sobre a degradação da eficácia da obtenção dos documentos relevantes numa janela de contexto longa, são coisas diferentes. (para além disso o paper é antigo, ainda do tempo do GPT 3.5, e ignora as mais recentes arquiteturas RWKV e Hyena, orientadas para terem uma melhor performance sobre contextos mais longos).
O paper reverte para uma falha fundamental em janelas de contexto, que nem sequer sao de tamanho suficiente, o que torna os modelos inuteis para substituir um trabalhador humano em boa parte das tarefas necessárias nas empresas (posso generalizar a organizaçoes).
Editado pela última vez por BearManBull em 30/8/2025 0:50, num total de 2 vezes.
“It is not the strongest of the species that survives, nor the most intelligent, but rather the one most adaptable to change.”
― Leon C. Megginson
― Leon C. Megginson
-
- Mensagens: 11973
- Registado: 15/2/2011 11:59
- Localização: 22
Re: A Revolução da Inteligencia Artificial
Rolling_Trader Escreveu:BearManBull Escreveu:Xiça outra vez com isto.
Claro que nao pensa, mas os LLMs em alguns aspectos emulam pensamento humano...
Não, uma LLM nem sequer emula o pensamento humano. O ser humano não escreve escolhendo as palavras com base em probabilidades.
Isso é o mesmo que dizer que um robot nao emula o movimento humano porque o robot é metal e circuitos electricos e o humano é carne e osso.
Emular =/= Copiar
Emular é obter resultados similares com abordagens diferentes.
Emular
to try to be like (someone or something you admire)
She grew up emulating her sports heroes.
artists emulating the style of their teachers
to copy something achieved by someone else and try to do it as well as they have:
1
a
: to strive to equal or excel
b
: imitate
especially : to imitate by means of an emulator
2
: to equal or approach equality with
“It is not the strongest of the species that survives, nor the most intelligent, but rather the one most adaptable to change.”
― Leon C. Megginson
― Leon C. Megginson
-
- Mensagens: 11973
- Registado: 15/2/2011 11:59
- Localização: 22
Re: A Revolução da Inteligencia Artificial
MarcoAntonio Escreveu:não queria dizer emular no sentido da analogia acima
Quem falou em analogia?
Nao disse absolutamente nada de que o processo interno de LLMs fosse x, y ou z.
“It is not the strongest of the species that survives, nor the most intelligent, but rather the one most adaptable to change.”
― Leon C. Megginson
― Leon C. Megginson
-
- Mensagens: 11973
- Registado: 15/2/2011 11:59
- Localização: 22
Re: A Revolução da Inteligencia Artificial
MarcoAntonio,
No post referente ao ranking do LMArena, saliento uma curiosidade nos modelos Text-to-Image
Em primeiro lugar, está o gemini-2.5-flash-image-preview, que à primeira vista pode ser confundido com um modelo já estabelecido do Gemini.
Na realidade foi um modelo que apareceu a semana passada, com o codename de "Nano Banana" e ninguém sabia que era da Google.
O lançamento oficial foi feito dia 26 de Agosto, e a descrição do modelo pode ser encontrada aqui
Neste momento está disponível no Google AI Studio, e é totalmente gratuito sendo classificado com um dos melhores e mais rápidos geradores de imagem destronando o ChatGPT e sendo apelidado de "Photoshop Killer"
Um exemplo, muito básico, pedi ao "Nano Banana" para gerar o teu avatar em 4 ângulos diferentes, sem mudar elementos da imagem original.
Eis o resultado:
No post referente ao ranking do LMArena, saliento uma curiosidade nos modelos Text-to-Image
Em primeiro lugar, está o gemini-2.5-flash-image-preview, que à primeira vista pode ser confundido com um modelo já estabelecido do Gemini.
Na realidade foi um modelo que apareceu a semana passada, com o codename de "Nano Banana" e ninguém sabia que era da Google.
O lançamento oficial foi feito dia 26 de Agosto, e a descrição do modelo pode ser encontrada aqui
Neste momento está disponível no Google AI Studio, e é totalmente gratuito sendo classificado com um dos melhores e mais rápidos geradores de imagem destronando o ChatGPT e sendo apelidado de "Photoshop Killer"
Um exemplo, muito básico, pedi ao "Nano Banana" para gerar o teu avatar em 4 ângulos diferentes, sem mudar elementos da imagem original.
Eis o resultado:
- Anexos
-
- front.jpg (11.63 KiB) Visualizado 6868 vezes
-
- right2.jpg (9.57 KiB) Visualizado 6868 vezes
-
- left.jpg (10.45 KiB) Visualizado 6868 vezes
-
- left zoom.jpg (12.61 KiB) Visualizado 6868 vezes
-

- Mensagens: 435
- Registado: 1/1/2024 14:39
Re: A Revolução da Inteligencia Artificial
BearManBull Escreveu:
Claro que nao pensa, mas os LLMs em alguns aspectos emulam pensamento humano...
Emular uma PS nao é jogar na PS mas é como fosse o mesmo embora usando outro hardware. O resultado nao é exactamente o mesmo mas é aproximadamente o mesmo.
Um breve apontamento, talvez isto ajude um pouco na discussão...
Emular é um termo muito forte neste contexto. A esse propósito, eu usei o termo atrás mas coloquei entre aspas, não queria dizer emular no sentido da analogia acima, que diz respeito a correr o mesmo código (algoritmo) num hardware diferente. Um LLM não corre o mesmo algoritmo num hardware diferente, nós sabemos que a natureza dos processos é diferente: (i) as redes neuronais artificiais são vagamente inspiradas nas estruturas biológicas, mas não operam da mesma forma, sabemos bem isso; (ii) além disso, sabemos também que os processos em si não são os mesmos. Muito embora haja ainda bastante que desconhecemos sobre o funcionamento dos nossos cérebros, sabemos o suficiente sobre eles e sobre as redes neuronais artificiais para percebermos que os processos são distintos. Além de serem distintos, a pipeline é marcadamente diferente também, remeto de novo para o meu post atrás onde assinalo que o processo está, em larga medida, invertido: o core (núcleo) do processo num LLM é um modelo linguístico, a aparência de inteligência ou raciocínio emerge da linguagem; nos humanos, a linguagem emerge da inteligência e dos processos cognitivos/mentais, é uma invenção nossa (ainda que se possa alegar que acabe por influenciar a forma como actuamos intelectualmente).
Ontologicamente, os processos são portanto diferentes. Há uma aparência de processo semelhante mas é superficial.
Há no entanto uma discussão corrente se não será possível, em termos funcionais, os processos se equipararem. Dito de outra forma, atingir um fim semelhante (uma forma alternativa de inteligência) através de um processo diferente, através de mecanismos processuais alternativos. Mas não chegamos lá, isto parece-me relativamente pacífico no contexto actual. O que há é grosso modo duas escolas de pensamento, uma funcional/pragmática e outra fenomenológica/ontológica. Pessoalmente, inclino mais para a segunda (ainda que sem certezas absolutas), e suspeito que a consciência é um elemento importante para aquilo que denominamos de inteligência (talvez as máquinas precisem de atingir o estágio em que elas próprias são entidades conscientes, pois essa poderá ser a "cola" que dá a coesão e a persistência característica do processo inteligente em si).
Mas, enfim, não me queria alongar muito agora. Quero apenas indicar que estou convencido de que há limitações processuais importantes na tecnologia actual e que as limitações/falhas que o bear está a apontar têm raiz quer em limitações práticas de recursos e de maturação da tecnologia, quer em aspectos mais fundamentais da arquitectura dos modelos (conforme já tinha exposto mais atrás).
FLOP - Fundamental Laws Of Profit
1. Mais vale perder um ganho que ganhar uma perda, a menos que se cumpra a Segunda Lei.
2. A expectativa de ganho deve superar a expectativa de perda, onde a expectativa mede a
__.amplitude média do ganho/perda contra a respectiva probabilidade.
3. A Primeira Lei não é mesmo necessária mas com Três Leis isto fica definitivamente mais giro.
-
- Administrador Fórum
- Mensagens: 41980
- Registado: 4/11/2002 22:16
- Localização: Porto
Re: A Revolução da Inteligencia Artificial
BearManBull Escreveu:Xiça outra vez com isto.
Claro que nao pensa, mas os LLMs em alguns aspectos emulam pensamento humano...
Não, uma LLM nem sequer emula o pensamento humano. O ser humano não escreve escolhendo as palavras com base em probabilidades.
Se o resultado final é algo parecido ao que um humano escreveria isso em nada tem a ver com a forma como se chega lá, que em nada é parecido ao pensamento humano.
BearManBull Escreveu:Aqui paper que relata justamente os problemas dos long contexts que mesmo longos continuam a nao ser suficientemente longos para substituir determinados profissionais em escala na minha opiniao.
Aqui posso parafrasea-lo e dizer "Xiça outra vez com isto.".
O paper que citou não diz que as janelas de contexto não são "suficientemente longos", disserta sim sobre a degradação da eficácia da obtenção dos documentos relevantes numa janela de contexto longa, são coisas diferentes. (para além disso o paper é antigo, ainda do tempo do GPT 3.5, e ignora as mais recentes arquiteturas RWKV e Hyena, orientadas para terem uma melhor performance sobre contextos mais longos).
Novamente, ao "atirar" 50 documentos para uma janela de contexto, a LLM "simplesmente" divide-os em tokens e distribui pesos durante o processo de inferência. Isso vai obviamente limitar a precisão da resposta quando comparada ao treino ou fine-tuning prévio de um modelo sobre esses mesmos documentos.
Mas desisto de lhe tentar explicar as complexidades das arquiteturas envolvidas dado que você, mesmo com um documento de research à frente, tira uma conclusão diametralmente oposta à da publicada no paper.
-
- Mensagens: 435
- Registado: 1/1/2024 14:39
Re: A Revolução da Inteligencia Artificial
MarcoAntonio Escreveu:É aqui que eu julgo que ainda há bastante para / por explorar, nomeadamente na engenharia dos sistemas, para vermos realmente o impacto real da tecnologia as is (isto é, mesmo que o desempenho da AI, sem mudar significativamente a arquitectura ou paradigma, não avance muito do ponto em que estamos agora).
Concordo, um agente orquestrador que actuaria como cola entre passos pode ser uma alternativa. Divide to conquer.
MarcoAntonio Escreveu:Por enquanto, bigger/better tem sido o foco da Google, OpenAI e companhia (o GPT5 talvez tenha já dado um quê de mudança de direcção) mas, mesmo que os principais players se foquem na capacidade bruta dos modelos, há o potencial para o resto do ecossistema para tentar retirar o melhor partido dos modelos existentes (como por exemplo, aplicações especializadas).
Esse foco tem vindo a ser demonstado que nao está a dar frutos.
“It is not the strongest of the species that survives, nor the most intelligent, but rather the one most adaptable to change.”
― Leon C. Megginson
― Leon C. Megginson
-
- Mensagens: 11973
- Registado: 15/2/2011 11:59
- Localização: 22
Re: A Revolução da Inteligencia Artificial
Rolling_Trader Escreveu:Novamente reitero, isto não é pensamento, uma LLM não pensa!
Xiça outra vez com isto.
Claro que nao pensa, mas os LLMs em alguns aspectos emulam pensamento humano...
Emular uma PS nao é jogar na PS mas é como fosse o mesmo embora usando outro hardware. O resultado nao é exactamente o mesmo mas é aproximadamente o mesmo.
Daí ter usado italico nalgumas expressoes.
Aqui paper que relata justamente os problemas dos long contexts que mesmo longos continuam a nao ser suficientemente longos para substituir determinados profissionais em escala na minha opiniao.
Repara que para substituir um advogado num processo o LLM teria de ser capaz de manter o mesmo contexto (sem perdas) que o advogado mantem do caso do inicio o fim com toda a info desde o inicio ao fim do processo.
Lost in the Middle: How Language Models Use Long Contexts
Editado pela última vez por BearManBull em 29/8/2025 0:52, num total de 2 vezes.
“It is not the strongest of the species that survives, nor the most intelligent, but rather the one most adaptable to change.”
― Leon C. Megginson
― Leon C. Megginson
-
- Mensagens: 11973
- Registado: 15/2/2011 11:59
- Localização: 22
Re: A Revolução da Inteligencia Artificial
Já com uma base jeitosa, o GPT-5 não se conseguiu impor à frente (e bate marginalmente apenas o o3) em blind tests no LMArena.
Tem um bom desempenho em código, ficando ligeiramente à frente do Claude Opus 4.1 (os modelos da Anthropic têm estado entre os favoritos para developers e, como mencionei no tópico da Meta, consta que a própria Meta está a adopta-los internamente).
Entretanto, espera-se o Gemini 3.0 da Google ainda para este ano...
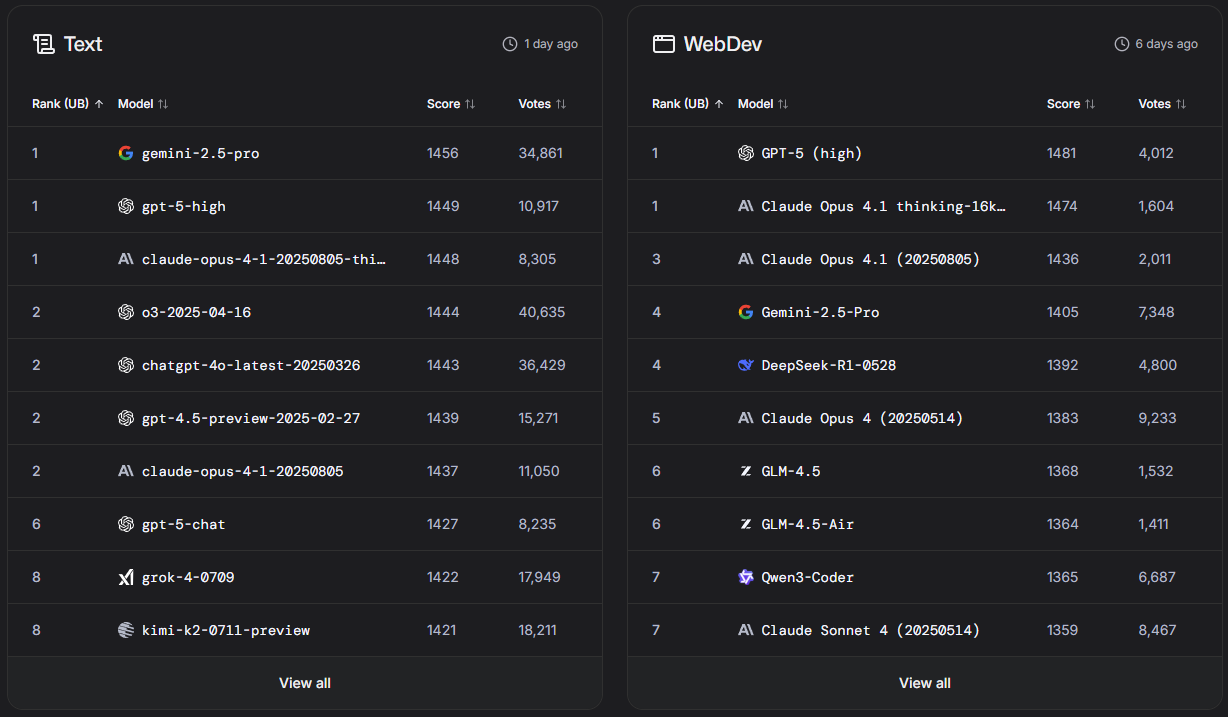
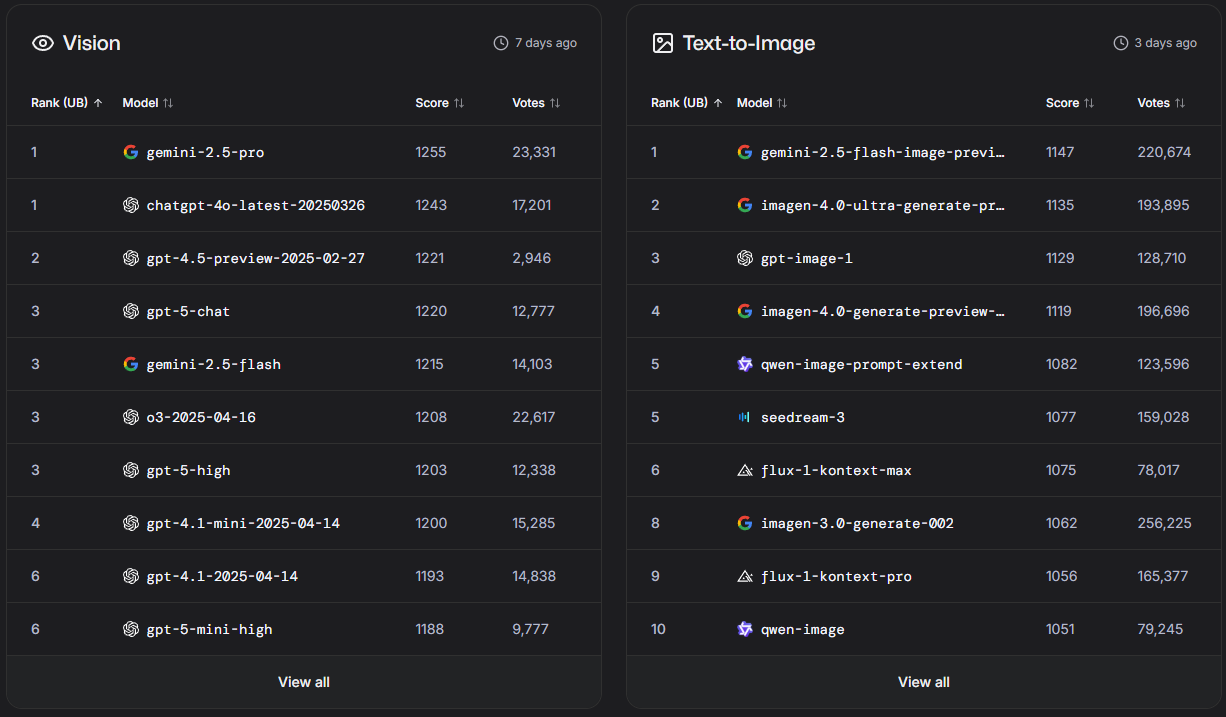
Para tarefas visuais (computer vision e geração de imagem). Aqui o Grok não aparece sequer, talvez não esteja incluído na pool se a tarefa envolver geração de imagens:
Tem um bom desempenho em código, ficando ligeiramente à frente do Claude Opus 4.1 (os modelos da Anthropic têm estado entre os favoritos para developers e, como mencionei no tópico da Meta, consta que a própria Meta está a adopta-los internamente).
Entretanto, espera-se o Gemini 3.0 da Google ainda para este ano...
Para tarefas visuais (computer vision e geração de imagem). Aqui o Grok não aparece sequer, talvez não esteja incluído na pool se a tarefa envolver geração de imagens:
FLOP - Fundamental Laws Of Profit
1. Mais vale perder um ganho que ganhar uma perda, a menos que se cumpra a Segunda Lei.
2. A expectativa de ganho deve superar a expectativa de perda, onde a expectativa mede a
__.amplitude média do ganho/perda contra a respectiva probabilidade.
3. A Primeira Lei não é mesmo necessária mas com Três Leis isto fica definitivamente mais giro.
-
- Administrador Fórum
- Mensagens: 41980
- Registado: 4/11/2002 22:16
- Localização: Porto
Re: A Revolução da Inteligencia Artificial
Creio que aqui o pressuposto tem sido o de utilizar o ChatGPT vanilla (ou outro LLM). Mas, para tarefas mais especializadas, orientadas a um objectivo mais específico, essa não vai ser por certo a melhor utilização do ChatGPT/LLM. A minha experiência na área jurídica é limitada (virtualmente inexistente), mas se me pedissem para “resolver” este problema, aquilo que me virá à cabeça mais imediatamente é criar um wrapper, com um ambiente ad hoc para o efeito, que aceda ao LLM via API (ou, se estiver disponível, um LLM local, eventualmente um "expert" para a tarefa em mãos). O wrapper poderia permitir manter a estratégia separada dos conteúdos materiais, e inclusivamente os documentos poderiam estar acessíveis separadamente para que o “assistente jurídico” aceda a cada um deles especificamente sempre que necessário. Algo dentro disto. Poderia ainda dispor de uma espécie de Constitutional AI, por forma a operar dentro dos parâmetros desejados para a tarefa também (nomeadamente, regras a cumprir no contexto jurídico, etc). Enfim, decompor a tarefa de desenvolver um (e avançar com o) processo judicial, de forma estruturada para o “assistente”, a correr sobre o LLM e com human-in-the-loop.
Isto para dizer que os limites da tecnologia não são necessariamente os que podem emergir facilmente numa utilização da versão vanilla, que foi fine-tuned para conversas e não, sei lá, para assistir num processo judicial.
É aqui que eu julgo que ainda há bastante para / por explorar, nomeadamente na engenharia dos sistemas, para vermos realmente o impacto real da tecnologia as is (isto é, mesmo que o desempenho da AI, sem mudar significativamente a arquitectura ou paradigma, não avance muito do ponto em que estamos agora).
Por enquanto, bigger/better tem sido o foco da Google, OpenAI e companhia (o GPT5 talvez tenha já dado um quê de mudança de direcção) mas, mesmo que os principais players se foquem na capacidade bruta dos modelos, há o potencial para o resto do ecossistema para tentar retirar o melhor partido dos modelos existentes (como por exemplo, aplicações especializadas).
Isto para dizer que os limites da tecnologia não são necessariamente os que podem emergir facilmente numa utilização da versão vanilla, que foi fine-tuned para conversas e não, sei lá, para assistir num processo judicial.
É aqui que eu julgo que ainda há bastante para / por explorar, nomeadamente na engenharia dos sistemas, para vermos realmente o impacto real da tecnologia as is (isto é, mesmo que o desempenho da AI, sem mudar significativamente a arquitectura ou paradigma, não avance muito do ponto em que estamos agora).
Por enquanto, bigger/better tem sido o foco da Google, OpenAI e companhia (o GPT5 talvez tenha já dado um quê de mudança de direcção) mas, mesmo que os principais players se foquem na capacidade bruta dos modelos, há o potencial para o resto do ecossistema para tentar retirar o melhor partido dos modelos existentes (como por exemplo, aplicações especializadas).
FLOP - Fundamental Laws Of Profit
1. Mais vale perder um ganho que ganhar uma perda, a menos que se cumpra a Segunda Lei.
2. A expectativa de ganho deve superar a expectativa de perda, onde a expectativa mede a
__.amplitude média do ganho/perda contra a respectiva probabilidade.
3. A Primeira Lei não é mesmo necessária mas com Três Leis isto fica definitivamente mais giro.
-
- Administrador Fórum
- Mensagens: 41980
- Registado: 4/11/2002 22:16
- Localização: Porto
Re: A Revolução da Inteligencia Artificial
BearManBull Escreveu:Distinguir trigo do joio é uma capacidade que têm neste momento altamente desenvolvida para prompts curtos.
A expressão "Distinguir o trigo do joio" significa discernimento e julgamento, características intrínsecas do pensamento.
Uma LLM, por definição, opera com base em padrões estatísticos e na probabilidade de uma palavra ou frase seguir outra, portanto não pensa, logo esta sua afirmação está tecnicamente incorreta
BearManBull Escreveu:Algo que faz falta sao cadeias de raciociinio (context window amplas)
Tal como o MarcoAntonio referiu, cadeia de raciocínio (Chain of Thought, ou CoT para abreviar) não é equivalente a context window, são dois conceitos separados.
O Chain of Thought exercido automaticamente pelos "Reasoning Models" atuais é conseguido através da modificação interna da prompt do utilizador para forçar a LLM, antes de dar a resposta final, a definir uma estratégia de pensamento que decomponha o problema. Essa pensamento é adicionado à janela de contexto e alimentará depois a resposta final da IA fazendo uma otimização probabilística da resposta para ser mais correta do que se esta etapa não fosse efetuada.
Novamente reitero, isto não é pensamento, uma LLM não pensa! Não é aumentando a context window que se vai mudar este facto intrínseco à arquitetura das LLM.
BearManBull Escreveu:Quando a rede está treinada com os materiais necessários consegue-se uma boa matriz.
Exatamente. É aí que a verdadeira vantagem das LLM se evidencia, se os dados de treino (ou fornecidos por si) forem irrepreensíveis e completos e o "fine tuning" dos parâmetros e pesos da LLM se adequar à finalidade que você pretende, então as respostas são fantásticas.
Mas o que é que isso tem a ver com limitações à janela de contexto? Nada!
BearManBull Escreveu:No geral com LLMs consegue-se fazer um pouco de tudo grao a grao mas nao o todo.
Com uma LLM, com o devido fine tuning, com contexto factualmente correto, sem imprecisões ou contradições as LLM continuam a ser extremamente eficazes, podendo haver alguma degradação na qualidade das respostas à medida que se vai atingindo o limite da context window.
Agora, uma LLM é um modelo que processa tokens de liguagem natural, se lhe der contexto na forma de imagens, audio, ou vídeo são necessárias ferramentas adicionais para "fazer a ponte" entre os modelos visuais ou de áudio para linguagem natural e pode-se efetivamente ter uma degradação da qualidade da informação de contexto.
Mas lá está isso acontece porque a LLM não pensa, usa dados de treino e dados de contexto para dar respostas probabilísticas, se os dados estiverem errados ou incoerentes não espere milagres.
A arquitetura das LLM funciona tão bem quanto a qualidade dos dados de treino ou de contexto.
E o que é que tudo isto tem a ver com o tamanho da janela de contexto? Nada.
BearManBull Escreveu:Estao a falar de tokens, como se fossem pre cozinhados para ser consumidos pelo LLM e nao de informaçao difusa como é a realidade....
Na realidade é mesmo assim que as LLM funcionam, os tokens de treino já estão "pré cozinhados" (usando a sua expressão coloquial), otimizados nos parâmetros e respetivos pesos que compõem o modelo.
Já os dados de contexto que você lhe dá (na forma de texto livre, documentos ou imagens) são "cozinhados" pela própria LLM, mais tecnicamente serão convertidos em vetores e posteriormente acedidos via RAG (Retrieval Augmented Generation), no entanto a importância dada pela LLM a cada documento que você colocou no contexto é efetuado através da decisões da rede neuronal subjacente, ou seja sofrem, logo à partida, uma deturpação na medida em que não são validados por um ser humano, nem sujeitos a um criterioso processo de "fine tuning".
Com base nesta explicação, devia ficar claro para si que o problema não é a quantidade dos documentos de contexto, mas sim o facto de você delegar na LLM (um algoritmo não pensante) a responsabilidade de os usar da melhor forma.
Não espere milagres, é uma limitação arquitetural!
Se quer uma LLM à medida, treine uma e faça-lhe fine tuning
BearManBull Escreveu: já estou farto de dizer o ChatGPT nao come 50 PTTs e 100 Words que funcona bem com prompts atomicos mas que nao consegue digerir informaçao massiva de entrada.
Se os "50 PPTs" e os "100 Words" conseguirem ser linearmente convertidos em tokens de texto, se não tiverem informação errada ou incoerente entre si e não sejam factualmente incorretos ou incompatíveis com os dados de treino do "ChatGPT", então essa informação massiva será corretamente processada, desde que a sua prompt seja a mais indicada para obter a resposta que você pretende.
Num contexto massivo de informação, mesmo que correto, dada a arquitetura das LLM que já foi aqui explicada e re-explicada tanto por mim como pelo MarcoAntonio, é virtualmente impossível você fazer uma prompt eficaz para um objetivo final tão simples como "faz uma defesa eficaz para o José Sócrates com base nestas 10 toneladas de documentos do processo Marquês".
O facto de nem você, nem ninguém, conseguir fazer uma prompt eficaz para tal objetivo dantesco reside no simples facto de que, os dados de contexto (i.e. os documentos) não são dados de treino, ou seja, não foram revistos por seres humanos para validar a sua veracidade e consistência e mais importante não foram fine-tuned para servir o propósito que você pretende.
Portanto, é da sua responsabilidade, na sua prompt, direcionar a LLM a usar os documentos mais corretos durante o seu Chain of Thought, caso contrário a LLM irá fazer assunções erradas, escolhendo as probabilidades dos tokens da resposta com base nos embedings que "decidiu" serem os mais corretos.
É por isso que você constatou que prompts mais precisas, para tarefas mais curtas são mais eficazes.
A melhor analogia que posso fazer é a seguinte:
- Imagine um estagiário de direito, saído da faculdade.
Você dá-lhe todo o processo Marquês para as mãos e pede-lhe para "fazer uma defesa efetiva para José Sócrates".
Ora o estagiário pode ter tido 20 valores a todas as cadeiras, ter toda a legislação portuguesa memorizada, todos os livros de direito e procedimentos memorizados e ser um verdadeiro robot.
Mas, pergunto-lhe, qual seria a sua estratégia, enquanto advogado de defesa sénior, para treinar um júnior por muito bom que ele fosse?
- 1. Gastava duas horas a explicar passo a passo ao estagiário sobre como você montaria uma defesa (e esperaria, por milagre, que o estagiário produzisse algo de jeito), ou
2. Sentava-se ao lado do estagiário e ia orientando o mesmo, passo a passo e validando tudo o que ele faz, em cada fase deste processo intelectual?
O cerne da questão é que montar uma defesa é um processo intelectual, não é algo que possa ser mecanizado.
Você tem mais sucesso em prompts pequenas com as LLM porque está a adotar a opção 2 (a mais lógica). Você é o sénior, que sabe pensar, e está a a instruir o júnior, passo a passo, a dar-lhe tarefas pequenas que sabe que ele consegue fazer (enquanto aluno de direito), mas quem está em controlo do pensamento é você.
Portanto o problema reside no facto de que "As LLM não pensam" (por definição arquitetural) e não no facto de "As LLM não conseguem gerir grandes contextos de informação"
-
- Mensagens: 435
- Registado: 1/1/2024 14:39
Re: A Revolução da Inteligencia Artificial
Ok, mas mesmo que estejas a correr um LLM remoto, a janela de contexto é um budget mais ou menos fixo (corres o risco de encher a janela mais rapidamente e a partir daí o desempenho do modelo degrada-se mais depressa, expectavelmente). Claro que isto só é realmente importante se estiveres com um projecto (relativamente) grande em mãos, tipo uma conversa/interação que se arrasta.
FLOP - Fundamental Laws Of Profit
1. Mais vale perder um ganho que ganhar uma perda, a menos que se cumpra a Segunda Lei.
2. A expectativa de ganho deve superar a expectativa de perda, onde a expectativa mede a
__.amplitude média do ganho/perda contra a respectiva probabilidade.
3. A Primeira Lei não é mesmo necessária mas com Três Leis isto fica definitivamente mais giro.
-
- Administrador Fórum
- Mensagens: 41980
- Registado: 4/11/2002 22:16
- Localização: Porto
Re: A Revolução da Inteligencia Artificial
MarcoAntonio Escreveu:Penso que esta estimativa estará até algo por baixo. Um token tipicamente ronda 0.75 palavras (~1.3 tokens por palavra) em inglês. Como o "Os Maias" tem na ordem de 218 mil palavras (varia conforme a edição), isto dará na ordem de 290K tokens. 1M daria para cobrir cerca de 3.5 vezes "Os Maias" completo. No entanto, isto é utilizando o rácio no inglês (de qq das formas serve para uma ideia geral).
Sim, é possível, foi uma simplificação que fiz, com base até nas próprias métricas publicadas na página oficial, sobre "long context" do Gemini.
Provavelmente o tamanho de cada token até pode ser dependente da implementação de cada modelo, nunca investiguei a fundo esses pormenores.
MarcoAntonio Escreveu:Já agora, tendo a privilegiar largamente a interação com os LLM em inglês por várias razões e uma delas está conectada precisamente com isto (no geral resumem-se ao mesmo, expectativa de melhor desempenho): o português (assim como outras línguas) tende a precisar de mais tokens que o inglês; mais razões: o inglês permite linguagem mais precisa/inequivoca em certas áreas, especialmente técnicas, além dos modelos LLM tenderem a demonstrar, empiricamente, melhor desempenho com o inglês (para começar, são treinados com um corpora muito mais vasto em inglês).
Sim, por vezes também uso prompts exclusivamente em inglês quando quero dar primazia aos dados de treino do modelo. Efetivamente, apesar da maioria das LLM ser multilingue e ter dados de treino nas várias línguas suportadas, o que é facto é que, sendo o inglês uma das línguas mais faladas no mundo, a quantidade de informação escrita, pública na web, que pode serviu de base para treino é grotescamente maior do que a conseguimos encontrar em português.
No entanto, uso português se estiver a fazer RAG sobre documentos escritos na nossa língua claro.
Quanto ao léxico inglês requerer menos tokens que o Português, nem me tinha lembrado disso, mas é um facto sim. Aumentará a velocidade de inferência e poupará espaço na janela de contexto, mas, a menos que esteja a correr uma LLM local, não é algo com que esteja muito preocupado... a "fatura" não sou eu que a pago
-
- Mensagens: 435
- Registado: 1/1/2024 14:39
-

- Mensagens: 4060
- Registado: 15/3/2023 3:21
Re: A Revolução da Inteligencia Artificial
BearManBull Escreveu:Estao a falar de tokens, como se fossem pre cozinhados para ser consumidos pelo LLM e nao de informaçao difusa como é a realidade....
Aparentemente, estás agora a remeter precisamente para o que eu cobri num post mais atrás (se é que estou a entender o que estás a querer dizer). Ou queres transmitir algo fundamentalmente diferente do que eu expus aqui?
Os tokens não são nem "pré-cozinhados" nem "informação difusa" como é a realidade, são apenas a unidade técnica que o modelo usa para representar (ler, escrever e processar) texto. No texto que estavas a comentar, foi discutido enquanto métrica para medir o que caberá na janela de contexto para um documento concreto (por exemplo, um livro). Recorrendo a uma analogia, podemos falar de tokens na janela de contexto como bytes numa RAM.
BearManBull Escreveu:Bem novamente o mesmo.
Tenho um caso em tribunal tenho 50 documentos para que o GPT ler e gerar uma defesa um dos grandes problemas é incapacidade de ler esses 50 documentos, justamente por falta de context window.
Qual é a dimensão do conjunto desses 50 documentos (em palavras), por exemplo, consegues estimar? E se houver outro tipo de informação para lá de texto, também precisa de ser quantificado.
BearManBull Escreveu:O GTP é capaz de ler diagramas e imagens individuais mas quando é parte de um todo complexo nao.
Isto já não é bem verdade, não com as versões mais recentes do GPT, que são multimodais, que processam e mantêm na janela de contexto informação proveniente de diferentes fontes (texto e imagens). Existe um limite quantitativo (a dimensão da janela de contexto) e que podemos estimar (ie, verificar se a quantidade de materiais cabe ou não na janela de contexto). Mas alegar que o GPT não consegue ler diagramas e imagens individuais como parte de um todo complexo, já não é bem o que se passa actualmente com os modelos superiores e multimodais já disponíveis.
Agora, para lá das limitações quantitativas (capacidade de armazenamento em termos de janela de contexto) que possam existir, existem limitações qualitatitvas, que derivam da arquitectura dos modelos (limitações processuais, para não dizer mesmo fenomenológicas se quisermos p.e. discutir o que é verdadeira inteligência, mas isso remete-nos para o post que eu já coloquei mais atrás).
Não é claro para mim ainda o que estás querer transmitir exactamente. Por exemplo, qual é exactamente a natureza da limitação ou limitações e porque é que dizes que não é preciso uma AGI para organizar uma estratégia num caso judicial grande e depois apontas para o que parece ser a degradação quando o modelo tenta lidar com tarefas complexas (tarefas iterativas, diferentes tipos de informação, mapeamento correcto com a realidade, etc).
FLOP - Fundamental Laws Of Profit
1. Mais vale perder um ganho que ganhar uma perda, a menos que se cumpra a Segunda Lei.
2. A expectativa de ganho deve superar a expectativa de perda, onde a expectativa mede a
__.amplitude média do ganho/perda contra a respectiva probabilidade.
3. A Primeira Lei não é mesmo necessária mas com Três Leis isto fica definitivamente mais giro.
-
- Administrador Fórum
- Mensagens: 41980
- Registado: 4/11/2002 22:16
- Localização: Porto
Re: A Revolução da Inteligencia Artificial
MarcoAntonio Escreveu:Não consigo entender o que estás a escrever / querer transmitir.
Bem novamente o mesmo.
Tenho um caso em tribunal tenho 50 documentos para que o GPT ler e gerar uma defesa um dos grandes problemas é incapacidade de ler esses 50 documentos, justamente por falta de context window.
Novamente a realidade nao se limita a palavras existem diagramas, imagens.
O GTP é capaz de ler diagramas e imagens individuais mas quando é parte de um todo complexo nao.
“It is not the strongest of the species that survives, nor the most intelligent, but rather the one most adaptable to change.”
― Leon C. Megginson
― Leon C. Megginson
-
- Mensagens: 11973
- Registado: 15/2/2011 11:59
- Localização: 22
Re: A Revolução da Inteligencia Artificial
MarcoAntonio Escreveu:Rolling_Trader Escreveu:Para contextualizar, 1500 páginas são 2 cópias integrais dos "Maias" de Eça de Queiroz, um dos livros mais extensos da literatura portuguesa, com 720 páginas. Se quiser pegar noutras obras mais pequenas do Eça, equivale a mais de 4 cópias de "As Pupilas do Senhor Reitor" e a mais de 7 cópias do "Amor de Perdição".
Penso que esta estimativa estará até algo por baixo. Um token tipicamente ronda 0.75 palavras (~1.3 tokens por palavra) em inglês. Como o "Os Maias" tem na ordem de 218 mil palavras (varia conforme a edição), isto dará na ordem de 290K tokens. 1M daria para cobrir cerca de 3.5 vezes "Os Maias" completo. No entanto, isto é utilizando o rácio no inglês (de qq das formas serve para uma ideia geral).
Já agora, tendo a privilegiar largamente a interação com os LLM em inglês por várias razões e uma delas está conectada precisamente com isto (no geral resumem-se ao mesmo, expectativa de melhor desempenho): o português (assim como outras línguas) tende a precisar de mais tokens que o inglês; mais razões: o inglês permite linguagem mais precisa/inequivoca em certas áreas, especialmente técnicas, além dos modelos LLM tenderem a demonstrar, empiricamente, melhor desempenho com o inglês (para começar, são treinados com um corpora muito mais vasto em inglês).
Estao a falar de tokens, como se fossem pre cozinhados para ser consumidos pelo LLM e nao de informaçao difusa como é a realidade....
“It is not the strongest of the species that survives, nor the most intelligent, but rather the one most adaptable to change.”
― Leon C. Megginson
― Leon C. Megginson
-
- Mensagens: 11973
- Registado: 15/2/2011 11:59
- Localização: 22
Re: A Revolução da Inteligencia Artificial
Não consigo entender o que estás a escrever / querer transmitir.
FLOP - Fundamental Laws Of Profit
1. Mais vale perder um ganho que ganhar uma perda, a menos que se cumpra a Segunda Lei.
2. A expectativa de ganho deve superar a expectativa de perda, onde a expectativa mede a
__.amplitude média do ganho/perda contra a respectiva probabilidade.
3. A Primeira Lei não é mesmo necessária mas com Três Leis isto fica definitivamente mais giro.
-
- Administrador Fórum
- Mensagens: 41980
- Registado: 4/11/2002 22:16
- Localização: Porto
Re: A Revolução da Inteligencia Artificial
MarcoAntonio Escreveu:Vamos lá ver: janela de contexto (ampla) é uma questão de recursos do sistema, não de processo. Ao utilizar uma janela de contexto grande/enorme, não estás a mudar nada no processo (como o modelo “raciocina”); apenas a aumentar a quantidade de informação que entra/é mantida na janela de contexto.
Mas se é isso que estou a dizer.
Outra vez o mesmo que já estou farto de dizer o ChatGPT nao come 50 PTTs e 100 Words que funcona bem com prompts atomicos mas que nao consegue digerir informaçao massiva de entrada.
“It is not the strongest of the species that survives, nor the most intelligent, but rather the one most adaptable to change.”
― Leon C. Megginson
― Leon C. Megginson
-
- Mensagens: 11973
- Registado: 15/2/2011 11:59
- Localização: 22
Re: A Revolução da Inteligencia Artificial
Rolling_Trader Escreveu:Para contextualizar, 1500 páginas são 2 cópias integrais dos "Maias" de Eça de Queiroz, um dos livros mais extensos da literatura portuguesa, com 720 páginas. Se quiser pegar noutras obras mais pequenas do Eça, equivale a mais de 4 cópias de "As Pupilas do Senhor Reitor" e a mais de 7 cópias do "Amor de Perdição".
Penso que esta estimativa estará até algo por baixo. Um token tipicamente ronda 0.75 palavras (~1.3 tokens por palavra) em inglês. Como o "Os Maias" tem na ordem de 218 mil palavras (varia conforme a edição), isto dará na ordem de 290K tokens. 1M daria para cobrir cerca de 3.5 vezes "Os Maias" completo. No entanto, isto é utilizando o rácio no inglês (de qq das formas serve para uma ideia geral).
Já agora, tendo a privilegiar largamente a interação com os LLM em inglês por várias razões e uma delas está conectada precisamente com isto (no geral resumem-se ao mesmo, expectativa de melhor desempenho): o português (assim como outras línguas) tende a precisar de mais tokens que o inglês; mais razões: o inglês permite linguagem mais precisa/inequivoca em certas áreas, especialmente técnicas, além dos modelos LLM tenderem a demonstrar, empiricamente, melhor desempenho com o inglês (para começar, são treinados com um corpora muito mais vasto em inglês).
FLOP - Fundamental Laws Of Profit
1. Mais vale perder um ganho que ganhar uma perda, a menos que se cumpra a Segunda Lei.
2. A expectativa de ganho deve superar a expectativa de perda, onde a expectativa mede a
__.amplitude média do ganho/perda contra a respectiva probabilidade.
3. A Primeira Lei não é mesmo necessária mas com Três Leis isto fica definitivamente mais giro.
-
- Administrador Fórum
- Mensagens: 41980
- Registado: 4/11/2002 22:16
- Localização: Porto
Quem está ligado: